文章来源:
jodie
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至405936398@qq.com举报,一经查实,本站将立刻删除。
_期货基金_智行理财网")
在使用 Kylin 的时候,最重要的一步就是创建 cube 的模型定义,即指定度量和维度以及一些附加信息,然后对 cube 进行 build,当然我们也可以根据原始表中的某一个 string 字段(这个字段的格式必须是日期格式,表示日期的含义)设定分区字段,这样一个 cube 就可以进行多次build,每一次的 build 会生成一个 segment,每一个 segment 对应着一个时间区间的 cube,这些 segment 的时间区间是连续并且不重合的,对于拥有多个 segment 的 cube 可以执行 merge,相当于将一个时间区间内部的 segment 合并成一个。下面开始分析 cube 的 build 过程。
以手机销售为例,表 SALE 记录各手机品牌在各个国家,每年的销售情况。表 PHONE 是手机品牌,表 COUNTRY 是国家列表,两表通过外键与 SALE 表相关联。这三张表就构成星型模型,其中 SALE 是事实表,PHONE、COUNTRY 是维度表。
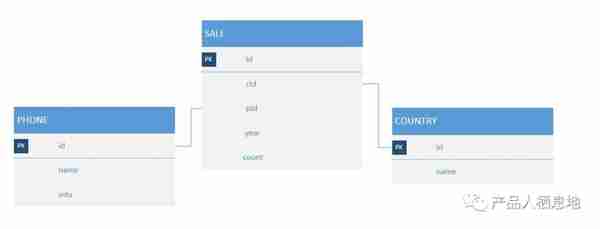
现在需要知道各品牌手机于 2010-2012 年,在中国的总销量,那么查询 SQL 为:
SELECT b.`name`, c.`NAME`, SUM(a.count)
FROM SALE AS a
LEFT JOIN PHONE AS b ON a.`pId`=b.`id`
LEFT JOIN COUNTRY AS c ON a.`cId`=c.`id`
WHERE a.`time` >= 2010 AND a.`time` <= 2012 AND c.`NAME` = "中国"
GROUP BY b.`NAME`
其中时间 (time), 手机品牌 (b.name,后文用phone代替),国家 (c.name,后文用country代替) 是维度,而销售数量 (a.count) 是度量。手机品牌的个数可用于表示手机品牌列的基度。各手机品牌在各年各个国家的销量可作为一个 cuboid,所有的 cuboid 组成一个 cube,如下图所示:

上图展示了有 3 个维度的 cube,每个小立方体代表一个 cuboid,其中存储的是度量列聚合后的结果,比如苹果在中国 2010 年的销量就是一个 cuboid。
在 kylin 的 web 页面上创建完成一个 cube 之后可以点击 action 下拉框执行 build 或者 merge 操作,这两个操作都会调用 cube 的 rebuild 接口,调用的参数包括:
1、cube 名,用于唯一标识一个 cube,在当前的kylin版本中 cube 名是全局唯一的,而不是每一个 project 下唯一的;
2、本次构建的startTime 和 endTime,这两个时间区间标识本次构建的 segment 的数据源只选择这个时间范围内的数据;对于 BUILD 操作而言,startTime 是不需要的,因为它总是会选择最后一个 segment 的结束时间作为当前 segment 的起始时间。
3、buildType 标识着操作的类型,可以是 ”BUILD”、”MERGE”和”REFRESH”。
04构建 Cube 过程
Kylin 中 Cube 的 Build 过程,是将所有的维度组合事先计算,存储于 HBase 中,以空间换时间,HTable 对应的 RowKey,就是各种维度组合,指标存在 Column 中,这样,将不同维度组合查询 SQL,转换成基于 RowKey 的范围扫描,然后对指标进行汇总计算,以实现快速分析查询。
整个过程如下图所示:
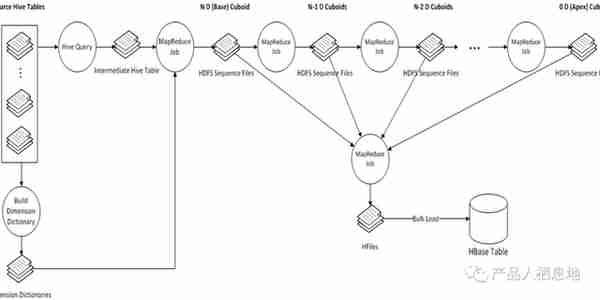
主要的步骤可以按照顺序分为几个阶段:
1、根据用户的 cube 信息计算出多个 cuboid 文件;
2、根据 cuboid 文件生成 htable;
3、更新 cube 信息;
4、回收临时文件。
每一个阶段操作的输入都需要依赖于上一步的输出,所以这些操作全是顺序执行的。下面对这几个阶段的内容细分为 11 步具体讲解一下:
4.1 创建Hive事实表中间表(Create Intermediate Flat Hive Table)
这一步的操作会新创建一个hive外部表,然后再根据cube中定义的星状模型,查询出维度和度量的值插入到新创建的表中,这个表是一个外部表,表的数据文件(存储在HDFS)作为下一个子任务的输入。
4.2 重新分配中间表(Redistribute Flat Hive Table)
在前面步骤,hive 会在 HDFS 文件夹中生成数据文件,一些文件非常大,一些有些小,甚至是空的。文件分布不平衡会导致随后的 MR 作业不平衡:一些 mappers 作业很快执行完毕,但其它的则非常缓慢。为了平衡作业,kylin 增加这一步“重新分配”数据。首先,kylin 获取到这中间表的行数,然后根据行数的数量,它会重新分配文件需要的数据量。默认情况下,kylin 分配每 100 万行一个文件。
4.3 提取事实表不同列值 (Extract Fact Table Distinct Columns)
在这一步是根据上一步生成的 hive 中间表计算出每一个出现在事实表中的维度列的 distinct 值,并写入到文件中,它是启动一个MR任务完成的,它关联的表就是上一步创建的临时表,如果某一个维度列的 distinct 值比较大,那么可能导致MR任务执行过程中的 OOM。
4.4 创建维度字典(Build Dimension Dictionary)
这一步是根据上一步生成的 distinct column 文件和维度表计算出所有维度的子典信息,并以字典树的方式压缩编码,生成维度字典,子典是为了节约存储而设计的。
每一个 cuboid 的成员是一个 key-value 形式存储在hbase中,key 是维度成员的组合,但是一般情况下维度是一些字符串之类的值(例如商品名),所以可以通过将每一个维度值转换成唯一整数而减少内存占用,在从 hbase 查找出对应的 key 之后再根据子典获取真正的成员值。
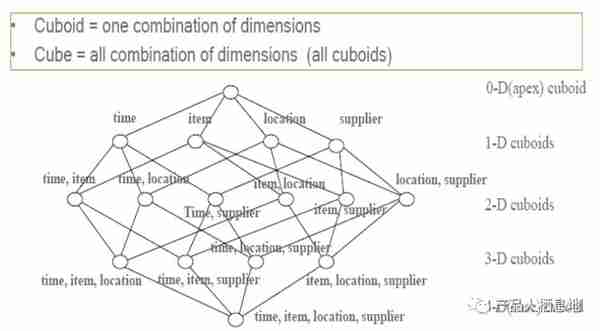
4.5 保存 Cuboid 的统计信息(Save Cuboid Statistics)
计算和统计所有的维度组合,并保存,其中,每一种维度组合,称为一个 Cuboid。理论上来说,一个 N 维的 Cube,便有 2 的 N 次方种维度组合,参考网上的一个例子,一个 Cube 包含time, item, location, supplier四个维度,那么组合(Cuboid)便有 16 种:
4.6 创建HTable
创建一个 HTable 的时候还需要考虑一下几个事情:
1、列簇的设置。
2、每一个列簇的压缩方式。
3、部署 coprocessor。
4、HTable 中每一个 region 的大小。
在这一步中,列簇的设置是根据用户创建 cube 时候设置的,在 HBase 中存储的数据 key 是维度成员的组合,value 是对应聚合函数的结果,列簇针对的是 value 的,一般情况下在创建 cube 的时候只会设置一个列簇,该列包含所有的聚合函数的结果;
在创建 HTable 时默认使用 LZO 压缩,如果不支持 LZO 则不进行压缩,在后面 kylin 的版本中支持更多的压缩方式;
kylin 强依赖于 HBase 的 coprocessor,所以需要在创建 HTable 为该表部署 coprocessor,这个文件会首先上传到 HBase 所在的 HDFS 上,然后在表的元信息中关联,这一步很容易出现错误,例如 coprocessor 找不到了就会导致整个 regionServer 无法启动,所以需要特别小心;region 的划分已经在上一步确定了,所以这里不存在动态扩展的情况,所以 kylin 创建 HTable 使用的接口如下:
public void createTable(final HTableDescriptor desc , byte[][] splitKeys)4.7 用Spark引擎构建Cube(Build Cube with Spark)
在 Kylin 的 Cube 模型中,每一个 cube 是由多个 cuboid 组成的,理论上有 N 个普通维度的 cube 可以是由 2 的 N 次方个 cuboid 组成的,那么我们可以计算出最底层的 cuboid,也就是包含全部维度的 cuboid(相当于执行一个 group by 全部维度列的查询),然后在根据最底层的 cuboid 一层一层的向上计算,直到计算出最顶层的 cuboid(相当于执行了一个不带 group by 的查询),其实这个阶段 kylin 的执行原理就是这个样子的,不过它需要将这些抽象成 mapreduce 模型,提交 Spark 作业执行。
使用 Spark,生成每一种维度组合(Cuboid)的数据。
Build Base Cuboid Data;Build N-Dimension Cuboid Data : 7-Dimension;Build N-Dimension Cuboid Data : 6-Dimension;……Build N-Dimension Cuboid Data : 2-Dimension;Build Cube。4.8 将Cuboid数据转换成HFile(Convert Cuboid Data to HFile)
创建完了 HTable 之后一般会通过插入接口将数据插入到表中,但是由于 cuboid 中的数据量巨大,频繁的插入会对 Hbase 的性能有非常大的影响,所以 kylin 采取了首先将 cuboid 文件转换成 HTable 格式的 Hfile 文件,再通过 bulkLoad 的方式将文件和 HTable 进行关联,这样可以大大降低 Hbase 的负载,这个过程通过一个 MR 任务完成。
4.9 导HFile入HBase表(Load HFile to HBase Table)
将 HFile 文件 load 到 HTable 中,这一步完全依赖于 HBase 的工具。这一步完成之后,数据已经存储到 HBase 中了,key 的格式由 cuboid 编号+每一个成员在字典树的id组成,value 可能保存在多个列组里,包含在原始数据中按照这几个成员进行 GROUP BY 计算出的度量的值。
4.10 更新Cube信息(Update Cube Info)
更新 cube 的状态,其中需要更新的包括 cube 是否可用、以及本次构建的数据统计,包括构建完成的时间,输入的 record 数目,输入数据的大小,保存到 Hbase 中数据的大小等,并将这些信息持久到元数据库中。
4.11 清理Hive中间表(Hive Cleanup)
这一步是否成功对正确性不会有任何影响,因为经过上一步之后这个 segment 就可以在这个 cube 中被查找到了,但是在整个执行过程中产生了很多的垃圾文件,其中包括:
1、临时的 hive 表;
2、因为 hive 表是一个外部表,存储该表的文件也需要额外删除;
3、fact distinct 这一步将数据写入到 HDFS 上为建立子典做准备,这时候也可以删除了;
4、rowKey 统计的时候会生成一个文件,此时可以删除;
5、生成 HFile 时文件存储的路径和 hbase 真正存储的路径不同,虽然 load 是一个 remove 操作,但是上层的目录还是存在的,也需要删除。
至此整个 Build 过程结束。
公众号:产品人栖息地
作者:DataSir 联云科技联合创始人、美团餐饮数据业务线产品总监、用友数据智能中台产品负责人、人人都是产品经理专栏作者。





